


Message Queues and bullMQ from a beginner's POV
Learnt about the message queues and implemented basic message queues using bullMQ, and hence, penning down my learnings here.


First up let's just get started with what. What are message queues?
What is a Message Queue?
To answer this question, let's have a look at queues first. What is a queue? A queue is basically a data structure that follows the FIFO (First In First Out) principle. This means the item that entered first will be the first one to leave. First In and First Out. A basic diagram for the queues:-

Now message queues are generally used in distributed systems for storing the messages in queue and executing them one by one asynchronously.
Here's a mandatory technical definition of message queue (generated by ChatGPT)
A message queue is a communication method used in distributed systems. It involves the use of a queue to store messages (or tasks) sent between different parts of a system. Applications or services can put messages into the queue, and other parts of the system can retrieve and process them asynchronously.
Now, taking a simple example:- You are at a shop and want to order pizza. The counter records your order and then performs the work of making the pizza and once finished, your pizza is delivered to you. Now, replace pizza with message/task. You give a task to the system and it takes the time and processes it and returns the result but in the meantime, you are doing nothing but standing in the queue. Things are happening synchronously one by one. This means that you are at the counter, places the order and then you are standing in the queue while your pizza is being processed (sorry baked) and once it is ready and you receive it, the next guy comes in and places the order, wait while other standing in the queue are waiting too (that's just how booking ticket from counter works btw and it sucks).
So, just like in the ticketing system, you don't want things that suck. So we try to do this more effectively. Since the process is taking long why make the other tasks wait? Hence the concept of message queues comes into the picture. There is one producer that receives all the requests and that is being pushed into the message queues. Like all orders of clients are collected by the counter(producer) and then tasks or orders are picked one by one according to the FIFO principle obviously and after the operation is performed (pizza is baked), the request is served to the client (worker). And in the meantime, you were free to do anything (in technical terms, the system is free to perform another task).
The "counter" is akin to the message producer, and the "pizza preparation" corresponds to the processing of tasks by the system and the consumer receiving the pizza order. The task is being performed asynchronously independent of other tasks just as your order is not dependent on other orders.

Managing errors and crashes in Message Queues
Now what if a task is corrupted? In that case, the worker might get affected and shut down for a while before respawning (hope you got that part covered), after restarting it will search for remaining messages/tasks in queues and operate on that. The corrupted task would get lost in this case with all the tasks being either completed or still left in the queue for processing.
To save messages from getting lost in case of errors, we use another queue for storing all the corrupted messages, let call this error queue for now.
With this error queue, we can store all the messages that have been tried once and resulted in the error. Now we can do one thing, after all the messages in the main queue are processed we can enqueue messages from the error queue and give it another try.
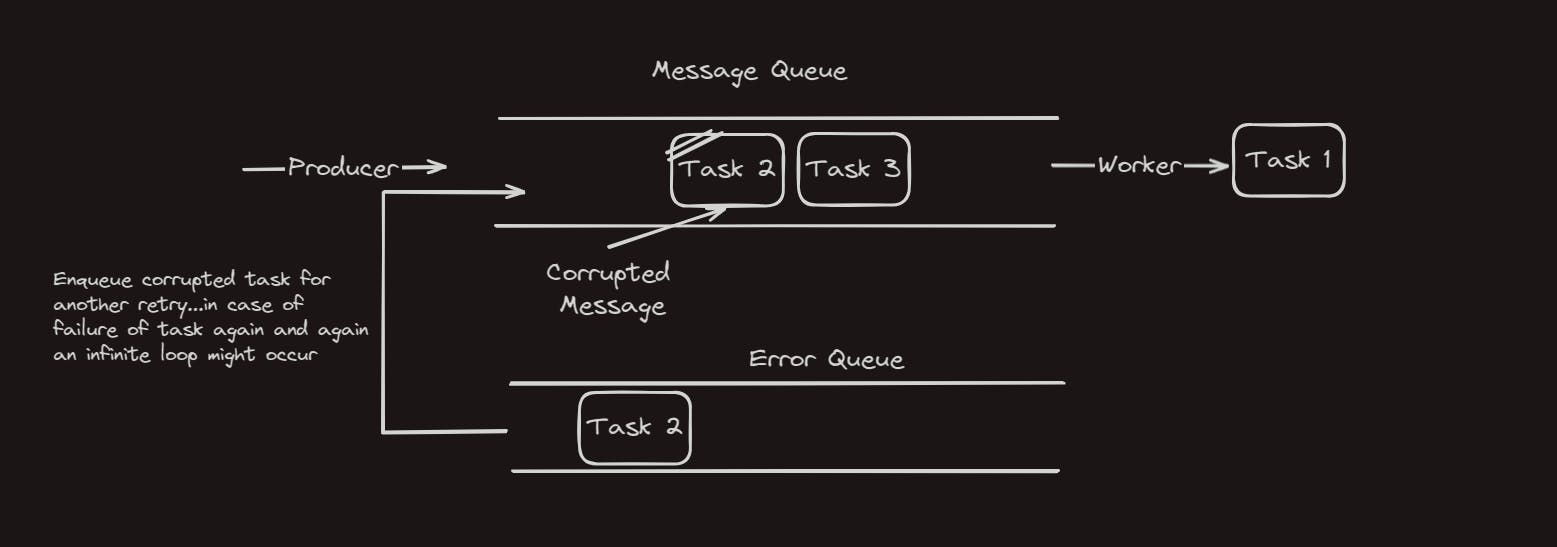
An infinite loop might occur in this case since the error queue will keep retrying and the task will keep ending up in the error queue. To avoid this condition we will use a separate worker for the error queue.
Each task that ends up in the error queue will be handled by its own worker. In successful retry, the task will be completed and in case of any errors, the task can simply be marked as corrupted and handled for the error case.
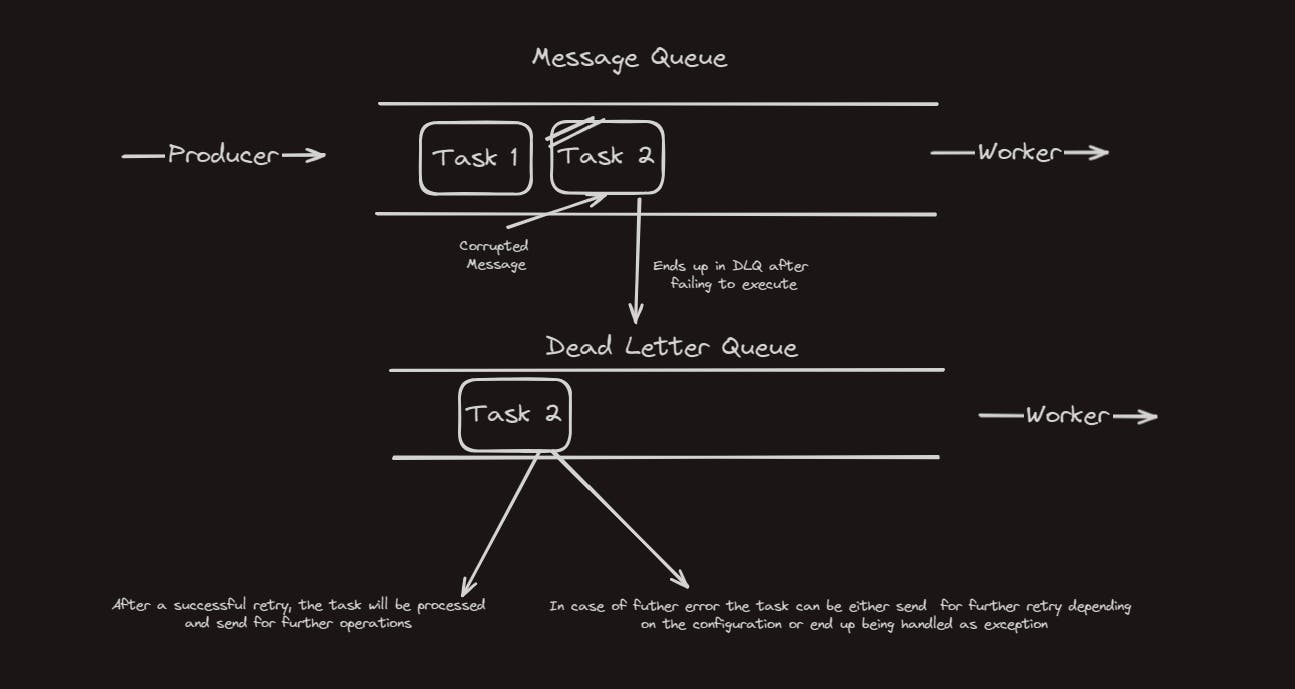
This concept is called the Dead Letter Queue.
Definition for Dead Letter Queue by ChatGpt (though no one asked for it)
A dead letter queue (DLQ) is like a safety net for messages that can't be processed normally. When a message can't be delivered or processed successfully, it's moved to the DLQ, where it waits for investigation or manual handling.
Producer and Worker using BullMQ
BullMQ is a Node.js library for handling jobs/messages queues and background processing tasks. It's easy to use and mainly used for managing and processing jobs efficiently.
For implementing message queues, you will need to implement two things, a producer responsible for creating and adding jobs to the queue and a worker for processing those jobs.
Here's a basic example using BullMQ:
Producer.js
// Setting up message queue using bullmq
const { Queue } = require("bullmq");
const queue = new Queue("job-queue", {
// Database config
connection: {
host: "127.0.0.1",
port: 6379,
},
});
// Adding a new job to message queue
const newJob = async () => {
console.log("Job recv in the worker!");
const res = await queue.add("the job", {
name: "UserName",
message: "Job Message",
date: new Date(),
});
console.log("Added to queue! ", "Id: ", res.id, "Data: ", res.data);
};
newJob();
Worker.js
// Worker to handle these jobs
const { Worker } = require("bullmq");
const worker = new Worker(
"job-queue",
async (job) => {
console.log("Recv job in the worker with id: ", job.id, "Data: ", job.data);
// Setting a fake promise (for processing jobs)
return new Promise((res, rej) =>
setTimeout(() => res(console.log("Job completed!")), 5000)
);
},
{
// Database configuration
connection: {
host: "127.0.0.1",
port: 6379,
},
}
);
So the producer.js here sets up the message queue and creates the new job/task. More jobs can be created inside the functions using different titles for each category. Now for processing these jobs, you will need to configure woker.js. Insider worker.js you can set up a worker and for each job, you can set up a function for performing necessary computations.
Note:- BullMQ uses redis as the database for storing these jobs. So first you will need to set up redis database and pass on details as configuration inside the producer.js and worker.js.
Wrapping Up the Learnings
Hence, the message queues can be used for performing several tasks parallelly helping in balancing load and increasing the efficiency. Producer and Worker are two important concepts relating to message queue implementation. Several libraries like RabbitMQ, BullMQ, ZeroMQ, ActiveMQ etc. can be used to implement message queues in Node.js.
References: